

A long time ago, I decided to show Bridgy‘s end users its raw logs. Like, raw logs. HTTP requests, database reads and writes, JSON objects, stack traces, etc. It’s an unusual UI feature, but it’s been an unqualified success, enough that when I built Bridgy Fed, I immediately included it and never looked back.
Whenever Bridgy does something nontrivial – poll a social network account, send a webmention, publish a post – I generally include a link to the server logs for that operation. Here’s an example, a series of timestamped plain text log messages from a poll of my Twitter account. They include initial config and parameters, account status, each individual Twitter API request, the results of those requests, how Bridgy interpreted them, HTTP requests to my web site, the subsequent actions Bridgy took and why, how the account’s status changed, and when the next poll is scheduled for.
These kinds of logs can answer a number of common user questions:
- Why isn’t Bridgy seeing this post?
- Why didn’t Bridgy send that webmention?
- Why isn’t Bridgy interpreting my microformats right?
- Why did Bridgy’s request to my web site fail?
- Why did Bridgy’s request to that social network fail?
- What exact data did Bridgy send in this webmention?
- What exact data did Bridgy send to that social network?
- Look what Bridgy did here, is this a bug?
- etc.
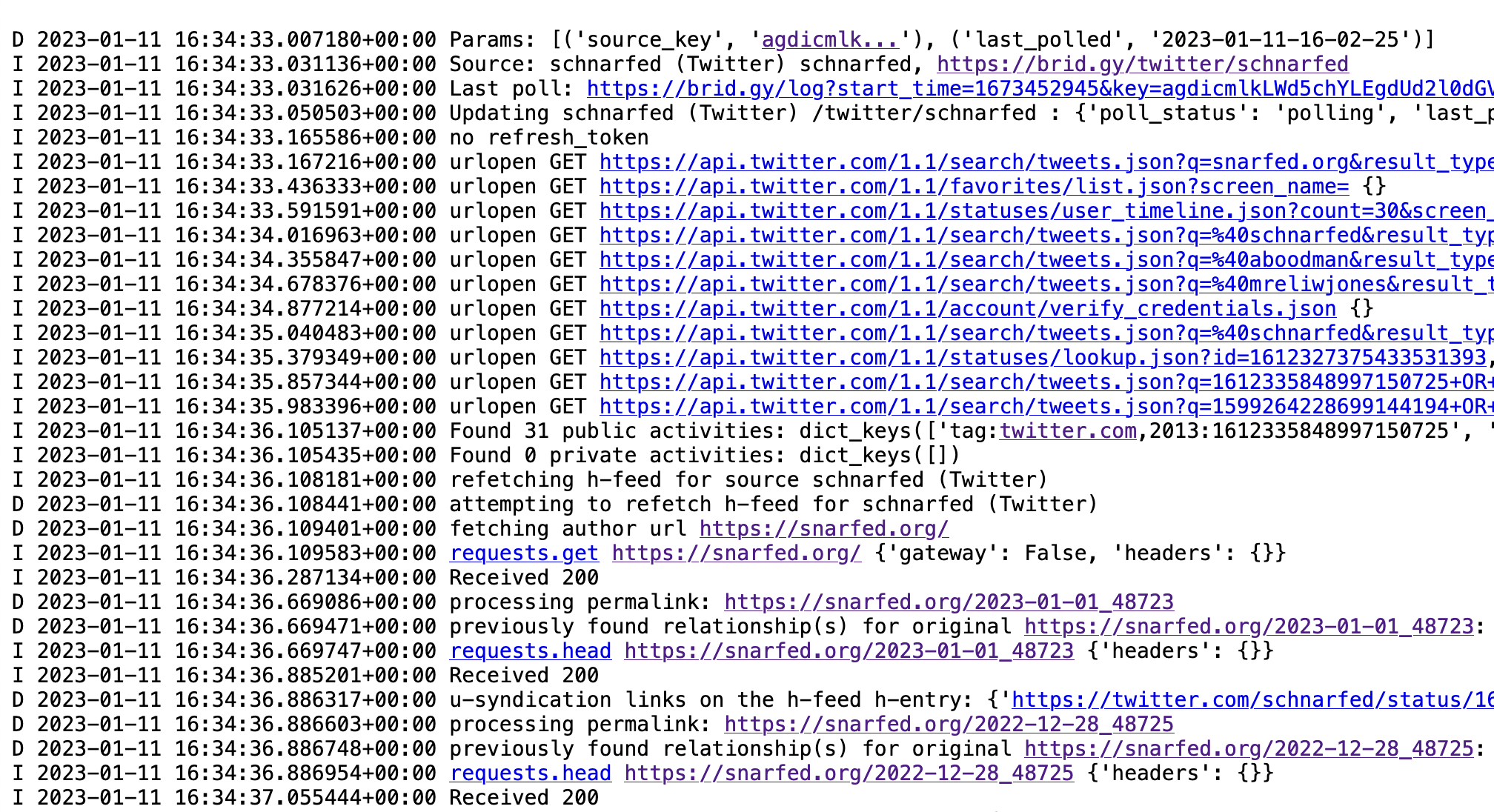
Why do I like this so much? In a word, ROI. I’m not a UX designer or frontend engineer, I dread building UI, so I’m always on the lookout for ways to minimize it or avoid it altogether. Unfortunately, Bridgy is a complex tool. It connects to dozens of external services and thousands of web sites, it has complex internal logic in a number of ways, and it requires involved, specific setup on users’ parts. I work hard to keep the docs complete and up to date, but in tech, we all know that users don’t read.
So, as a way to communicate a broad, deep range of complex information, logs give me tremendous bang for the buck. Plain text log messages are flexible, cheap, and widely supported in most infrastructure. I already include logging during development as an observability tool for myself. I had to build an extra handler to serve those logs to end users, but that was mostly straightforward. Mostly.
This isn’t for the faint of heart though. It’s a tricky idea with a number of drawbacks:
- It only works for relatively technical user bases. Plain text logs are not good general-purpose UI. Wading through a wall of fixed width text and technical jargon is akin to seeing the matrix. Bridgy’s user base is relatively technical, but that’s not the norm. For most mainstream users, it’s a non-starter.
- Furthermore, even if most of your users are technical, the fact that logs are bad UI means they may cause confusion in the minority who aren’t.
- Exposing raw logs is risky! Most services have credentials, private data, and other non-public information. Developers often try to keep those out of logs, but some always slips in. That’s not critical when logs are internal only, but as soon as you expose them publicly, any exposure is unacceptable. You have to sanitize all non-public information, or at least anything that the logged in user shouldn’t see. That work is tedious, detail-oriented, and error-prone.
- Similarly, logs air all of your dirty laundry. All those quick hacks, shortcuts, missing features, old legacy incompatibilities, internal design decisions, and straight up bugs are on full display for anyone willing to spend the time to look for them. This can be good, transparency and all, but still. You have to be ok with the world looking through your underwear drawer and second guessing everything you do.
Regardless, even considering all of those tradeoffs, I love the logs UI. It’s saved me – and users! – countless hours of support and debugging. Consider it next time you build something for developers or other technical people. As low effort, high return, “worse is better” UI goes, it’s one of my favorite techniques.
Likes
Bookmarks