

I just finished reading Charles Perrow‘s Normal Accidents, the classic book that examines why and how complex systems fail.
When it was published in 1984, the Internet and large distributed software systems were still nascent, so he focused on nuclear power plants, chemical plants, and marine and air traffic control. Even so, the parallels are remarkable: buffers and queues, throttles and safety valves, abuse of common subsystems, unexpected interactions, and incomplete and untrustworthy monitoring. Replace valves with network connections and gases with data, and a 1970s power plant meltdown looks a lot like a 2011 cloud platform outage.
The good news is, we’ve already learned some of Perrow’s lessons. As he drills into system architectures and accidents, he lays ground rules that we now know well. Component failures are routine; handle them with redundancy. Human errors are inevitable; catch them with safeguards. Still, systems are complex enough that unexpected interactions are common, especially during component failures. This leads to large scale failures: “normal accidents” in his world, outages in ours.
Continuing on familiar ground, Perrow builds a taxonomy of systems based on two criteria we know well: complexity of interaction between parts and coupling tightness between connected parts. Connecting this to failure rates, he concludes that systems with complex interactions and tight coupling are by far the most failure prone. Sound familiar?
The failure rate for linear, loosely coupled systems is low. The Post Office is a classic example. Interestingly, though, it’s also low in both linear, tight systems like assembly lines and complex, loose systems like universities. Both can fail, but the causes are straightforward. A system must be both complex and tightly coupled before it’s prone to accidents. This begs the question: can you prevent failures by making a system more linear, or by loosening its coupling? Perrow says yes.
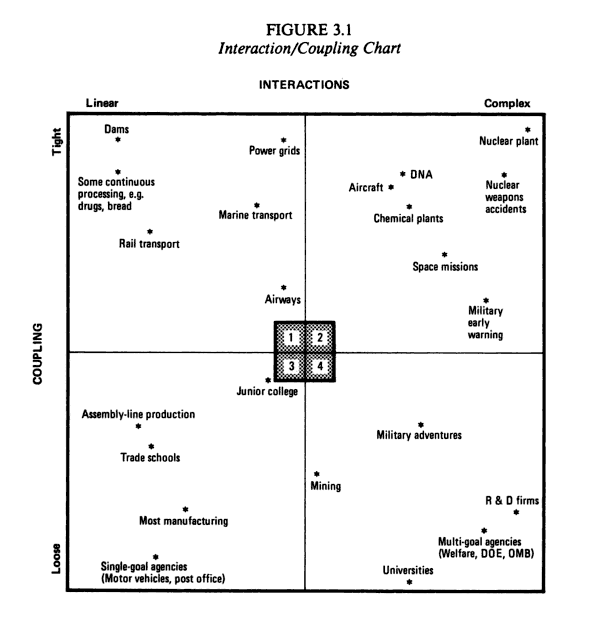
In software, loose coupling is common. For example, we know that replacing an RPC call with a queue can improve reliability, though at the cost of latency. Linearizing is less obvious, though, especially since it doesn’t always mean simplifying. Can we make that online app look more like an assembly line by separating data generation from serving? How about replacing real time indexing with a batch indexer? Can we turn that big hairy MapReduce into a pipeline?
Things get really interesting – and scary – when Perrow turns to look at operations. He argues that tightly coupled systems have little room for error, so they’re best run by centralized organizations. That works for linear systems too, since they’re generally well understood and can follow rote, by-the-book processes.
On the other hand, loosely coupled systems have slack to absorb individual errors, which allows for out-of-the-box thinking common in decentralized organizations. More importantly, complex systems demand decentralization, since unexpected interactions can often only be understood and handled by the people closest to them.
This puts us between a rock and a hard place. Tightly coupled systems need centralized ops; complex systems need decentralized. In the real world, centralized often wins, but that just means complex failures often go unnoticed or misdiagnosed for hours. If we can’t rearchitect a complex, tightly coupled system, are we doomed to run it poorly?
Many of the other conclusions apply too. We all know the common tension between engineering and ops: ship fast and automate vs safety, reliability, and control. Continuous integration has begun to bridge the gap between speed and safety, but Perrow’s data confirms that there’s no clear answer to automation vs. control. Automation improves efficiency, throughput, and some failure recovery, but hurts visibility, control, and flexibility on the part of human operators. Each has its own Achilles heel, and neither prevents failures entirely.

One particularly interesting point was externalities such as pressure from management to minimize costs and downtime. Perrow turns risk homeostasis on its head with example after example of technological safeguards that operators abuse to maintain the same accident rate while doing more, faster. Truckers who get better brakes, for example, compensate by driving faster downhill, which lets them do more jobs.
Similarly, when we firefight outages, the pressure to get the system back up can be overwhelming. We don’t have the time to fully investigate and understand what happened, so we guess and take shortcuts and clean up later. Usually this is the right choice, but not always.
Of course, there are clear differences between nuclear power plants and software. We’re not bound by the physical constraints on industrial systems, which is both good and bad. We update our systems quickly and often, sometimes making significant design changes. We have tools such as abstraction, reuse, and automated testing that our industrial colleagues don’t, or not to the same degree.
Do these differences make our systems less error prone? Or do we just use them to squeeze out more complexity and maintain the reliability status quo? Would designing more linearly help, as Perrow shows it did with some nuclear power plants? Have we learned to structure ops organizations any better? I don’t know, but I might at least have a better toolbox for these kinds of questions in the future.
Thanks to Mike Shields and Brent Chapman for recommending this book.
Pingback: Ryan Barrett
@schnarfed @efleis couldn’t agree more. Also found a ten-year timeline later in the book so feeling better about nuclear power ;)