

MLOps has emerged in the last few years to describe applying DevOps/SRE principles and practices to machine learning. It includes everything around data science and modeling: acquiring and preparing data, pruning feature sets, training and measuring and iterating models, deploying them to production, and monitoring their performance.
Here’s a very brief survey of the MLOps space, concepts, offerings, and recommendations, as of mid 2021.
Communities
A number of communities and related groups have emerged. AI Infrastructure is one of the most important; they hope to create structure and standards. User groups include MLOps.community, a Europe-centric group with a Slack and podcast, and MLOps World, a Canadian conference. The influential Towards Data Science blog frequently discusses MLOps, as do On Data Engineering and Datanami.
Rise of the Canonical Stack in Machine Learning and Maximizing ML Infrastructure Tools for Production Workloads are two good introductions to the overall space.
Lifecycle and components
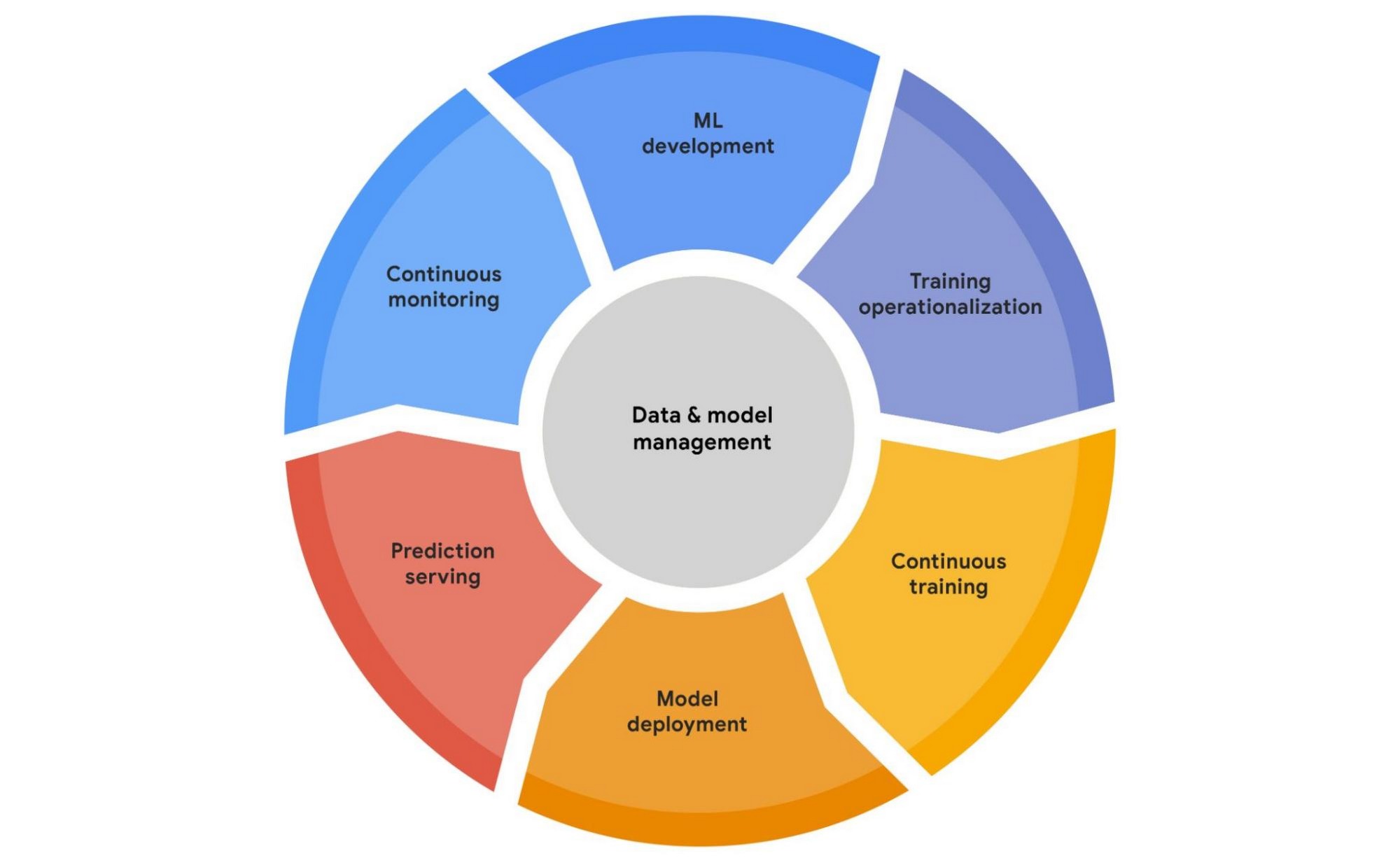 GCP Vertex AI’s take on lifecycle
GCP Vertex AI’s take on lifecycle
There are many takes on what constitutes the MLOps lifecycle and which tools and components it includes. There’s no single right answer, and you don’t need to choose one, but here’s a rough consensus:
- Data preparation
- Modeling
- Productionizing (deploy, monitor, iterate)
And here’s a set of possible components:
 AI Infrastructure’s MLOps stack
AI Infrastructure’s MLOps stack
- Data versioning and management
- Data cleaning and labelling
- Feature store
- Modeling, experimenting, training
- Code frameworks
- Data processing pipeline (training, ETL)
- Deployment and serving
- Monitoring
Offerings
As usual, early MLOps tools were first introduced in house at various companies doing ML in production, then offered by smaller independent vendors, then as standalone tools from the major cloud vendors, and finally as integrated product suites. Here’s a survey of the current offerings as of mid 2021.
Integrated suites
The big three cloud vendors – AWS, GCP, and Azure – all have comprehensive MLOps offerings: AWS Sagemaker, GCP Vertex AI, Azure ML. They’re all solid, substantial, and primarily serve customers already inside their respective ecosystems.
Major independent vendors include:
- Databricks, one of the largest, all in one
- Seldon, a premier deploy and monitoring solution
- Pachyderm, data versioning and pipeline
- Maiot, all in one, makes ZenML, open source reproducible modeling framework
- Allegro, experiment and training pipeline
The independent vendors are generally cloud-based, and often also integrate with one or more of the big three. Databricks seems more deeply tied to Azure, but supports all three.
Kubeflow and MLflow also earn mentions here as open source platforms that handle much of the MLOps lifecycle. Kubeflow is backed by Google, MLflow by Databricks.
Components
Here’s an (incomplete) collection of offerings for each component.
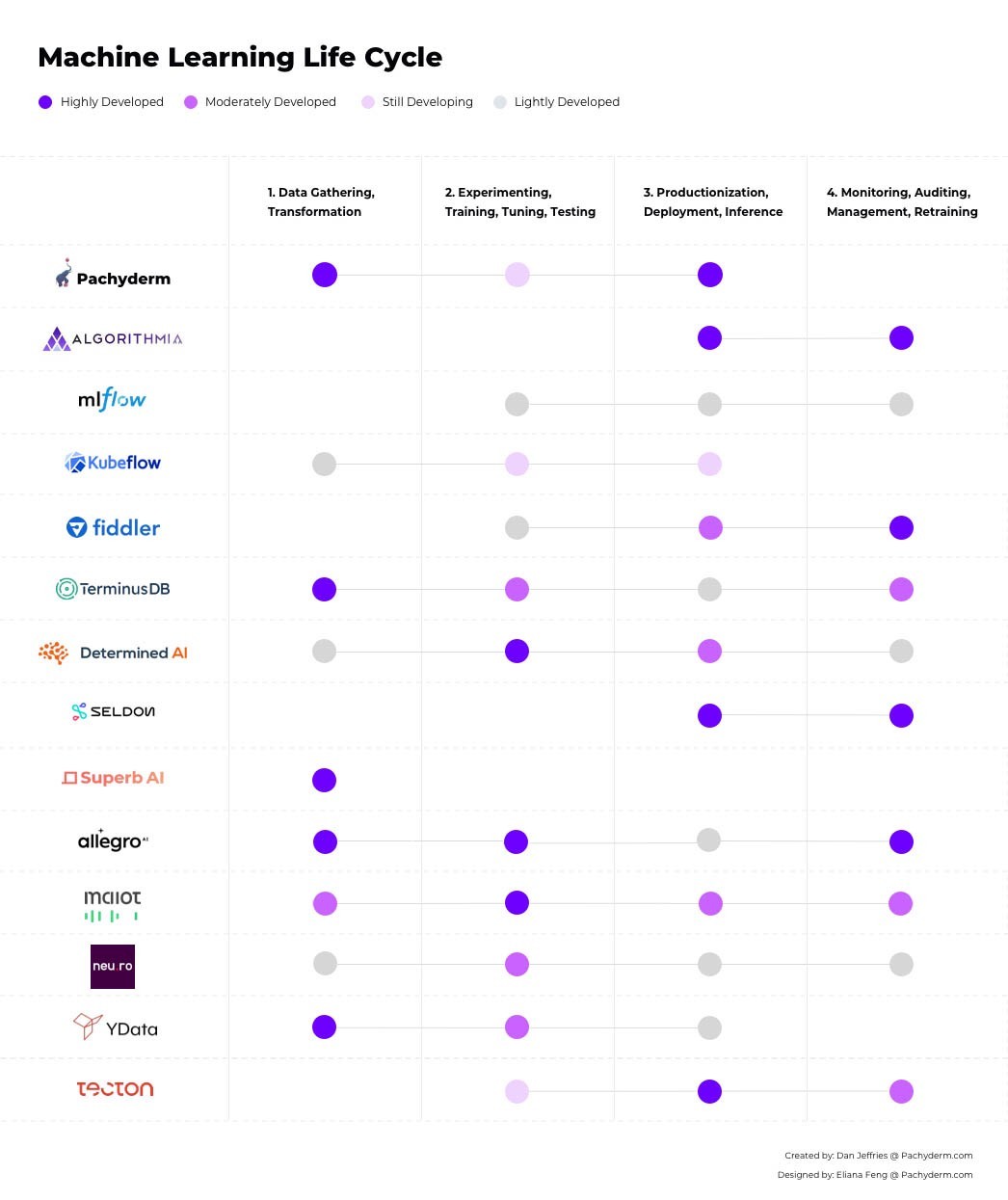 Towards Data Science’s vendor comparison
Towards Data Science’s vendor comparison
- Data management, versioning
- Pachyderm, DVC
- Data cleaning and labeling
- Lots! One of the most crowded parts of the market. Superb.ai, YData
- Feature store
- Feast, Tecton
- Modeling (experiments, training)
- Open source: TensorFlow Extended (TFX), HyperOpt, maiot, Pyro (GPU)
- Higher level: maiot, Allegro, Determined.ai
- Code frameworks
- TensorFlow, PyTorch, Stan
- Older: MXNet, Chainer
- Data pipeline
- SageMaker, Kubeflow, MLflow, Pachyderm, Allegro, Algorithmia, Neuro
- Open source, not ML specific:
- Batch: Airflow, Spark
- Streaming: Flink, Kafka, Storm, Keboola
- Deployment and serving
- Almost everyone! Azure ML, Vertex AI, SageMaker, Databricks, Algorithmia, Seldon, Kubeflow, Anyscale, Tensorflow, Pyro, BaseTen
- Monitoring
- MLflow, Seldon, Arize, Fiddler (focused on explainability)
Recommendations
Right now, MLOps work at most software shops with data science or machine learning is informal and often manual. You don’t need to immediately formalize all of it and buy a bunch of tools or services, but you probably want to at least start looking. Where to start depends on your specifics, but in many cases, monitoring is a good first candidate, possibly followed by deployment and serving at some places, feature extraction and store at others.
Many of the comprehensive suites are now mature and well supported, and Databricks is the most complete independent offering. Its MLflow is also one of the best tools for R&D and productionizing. Most contemporary ML pipelines aren’t deeply tied to any the big three, so Databricks and MLflow are often a good candidate for initial pilots.